Group Tracking
|
This page contains additional files for our publication on group tracking:
B. Lau, K.O. Arras and W. Burgard Files available for download
|
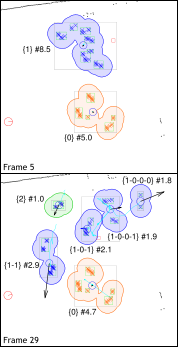 | |||||||||||||||||||||||||||
Explanations
The logs and the maps are stored in the formats used by the Carnegie Mellon Robotics Toolkit CARMEN. From these log files, our tracker uses the lines starting with ROBOTLASER1, i.e., laser range readings combined with odometry information. Additionally, the GLOBALPOS lines are read, which contain the global pose estimated by localization.
The ground truth (if available) is also stored in these log files. The corresponding lines start with the tag GTLABEL, and contain manually annotated information for the subsequent ROBOTLASER1 line. It contains foreground/background labels, tracks of individual people, and group tracks. The syntax is defined as follows:
GTLABEL <unlabeled> <people> <background> <occludedPeople> <peopleLinks> <groups> -1 timestamp hostname timestamp
| <unlabeled> | list of unlabeled clusters. In a completely labeled log file, this is just a '0'. |
| <people> | number of people followed by that number of of people clusters |
| <background> | number of background clusters followed by that number of background clusters |
| <occludedPeople> | number of occluded people followed by that number of people clusters |
| <peopleLinks> | number of people links followed by that number of link numbers |
| <groups> | number of groups followed by that number of groups |
| cluster | number of points follwed by x/y coordinate pairs (global coordinates) |
| link number | These numbers correspond to the IDs of people and occluded people in the last frame. If the person was outside the sensor field of view in the previous frame, the link number is -1. The IDs are implicitly given: they correspond to the position of a person in <people> for IDs from 0 to numPeople-1, and to the position of a person in <occludedPeople> for IDs from numPeople on. |
| group | number of people in the group followed by their ID (see last line) |
