TORO - News and Updates
2008-01-26
New version of TORO has been released that fixes some convergence problems
in 3D datasets (the distribution of the rotation error in 3D has changed).
2008-01-26
New version of TORO has been released that fixes some convergence problems
in 3D datasets (the distribution of the rotation error in 3D has changed).

(logo artwork by Christian Plagemann)
 |
Giorgio Grisetti, Cyrill Stachniss, Slawomir Grzonka, and Wolfram Burgard A Tree Parameterization for Efficiently Computing Maximum Likelihood Maps using Gradient Descent. Robotics: Science and Systems (RSS), Atlanta, GA, USA, 2007. paper (8 pg, pdf) |
 |
Grisetti Giorgio, Slawomir Grzonka, Cyrill Stachniss, Patrick Pfaff, and Wolfram Burgard Efficient Estimation of Accurate Maximum Likelihood Maps in 3D. In Proc. of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2007. paper (7 pg, pdf) -- WARNING: The math in this paper can cause convergence problems in 3D datasets resulting from the distribution of the rotation error. The implementation is fixed so that this issue does not arise. |

|
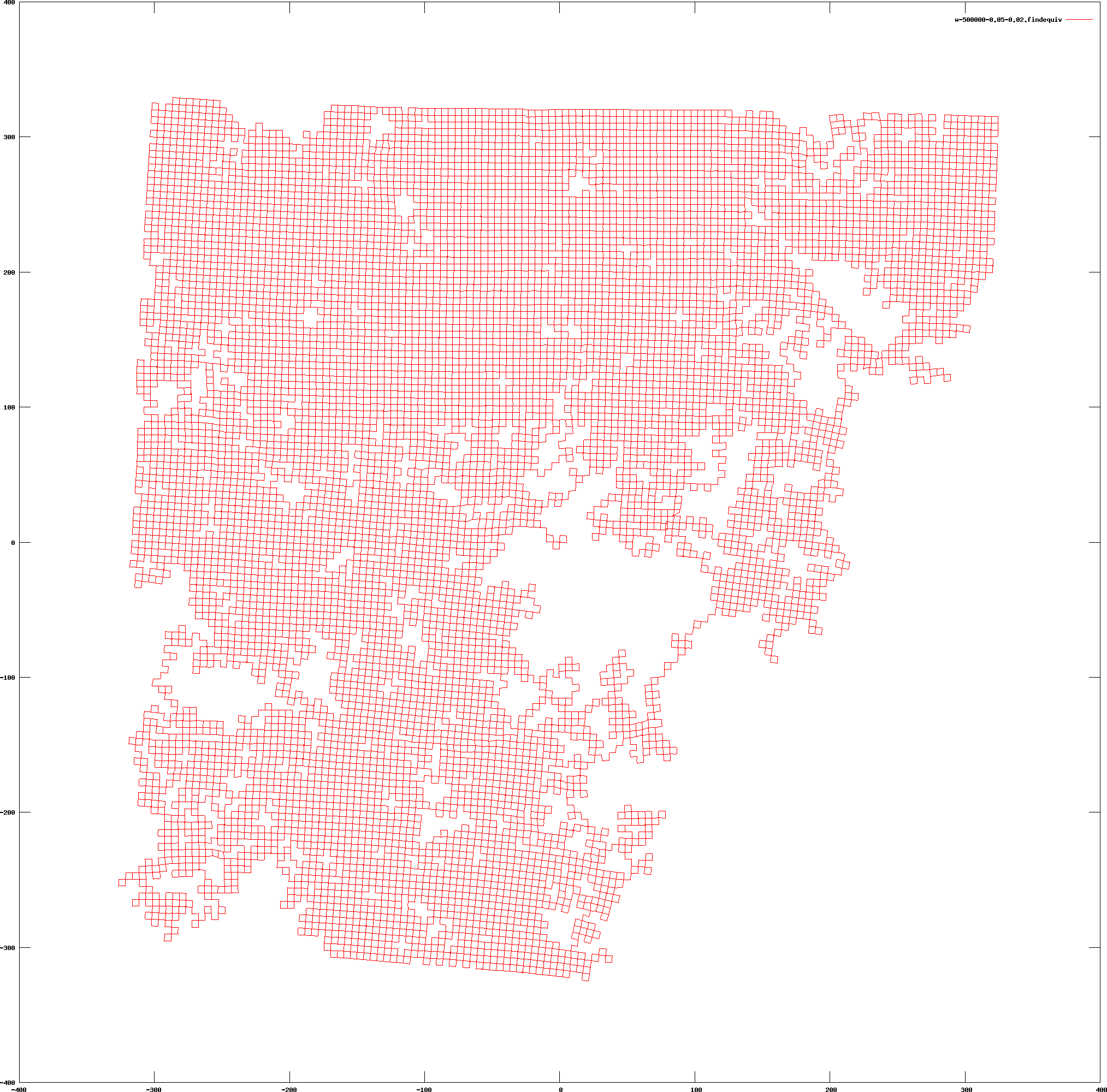
Corrected network Method: Our 3d approach (3d tree parameterization), no node reduction Result after 100 iterations |
|
Corrected network Method: Our approach (tree parameterization), no node reduction Size: 500.000 nodes/2 million constraints Noise: sigma-x/y=0.05, sigma-theta=0.02 Result after 100 iterations |

|
Corrected network Method: Our approach (tree parameterization), no node reduction Size: 200.000 nodes/1 million constraints Noise: sigma-x/y=0.01, sigma-theta=0.005 Result after 100 iterations |

|
Video of the individual iterations Method: Our approach (tree parameterization), no node reduction Size: 5.000 nodes/30.000 constraints |

|
Real world dataset: Intel Research Lab Video of the individual iterations Constraints are obtained via pair-wise scan-matching |
|
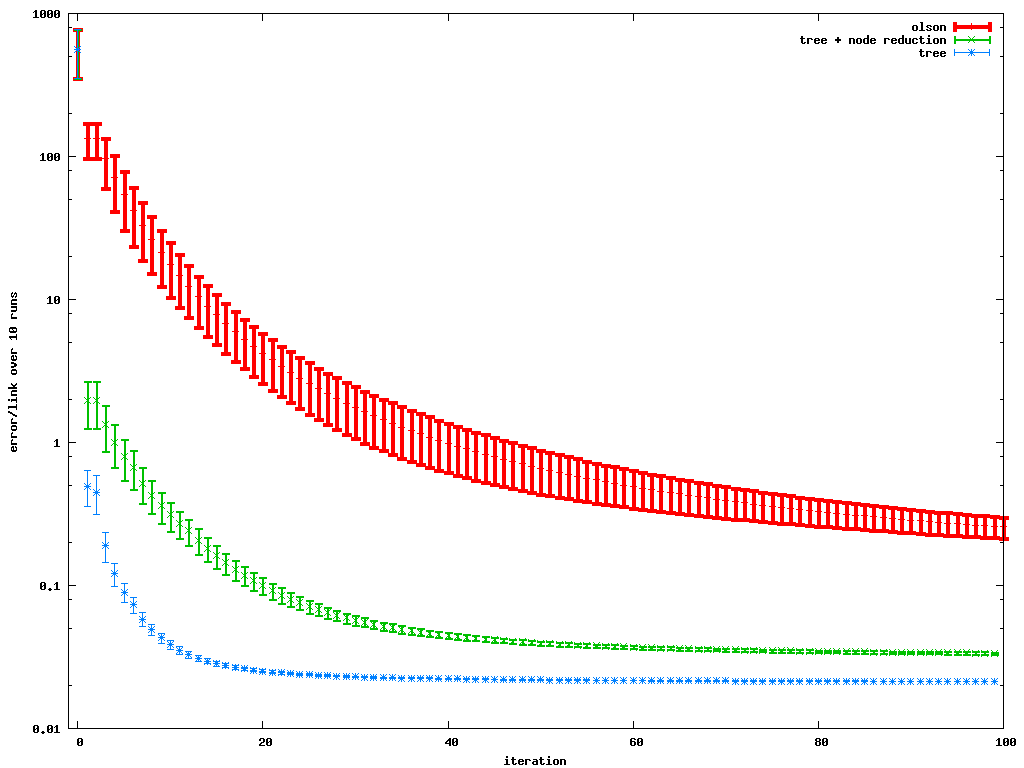
Comparison of the error per link per iteration Method: Olson's algorithm, our approach (tree parameterization) with and without node reduction Size: 5000 nodes Noise: sigma-x/y = 0.1, sigma-theta = 0.05 Confidence: 0.05 Note: Using the node reduction technique, the error per iteration decreases slower compared to the pure tree approach (it is log-scale). Each iteration, however, can be executed significantly faster (see Fig.6 in the RSS paper). |

|
Average path length for random networks of different size (Operations per constraint and iteration) |